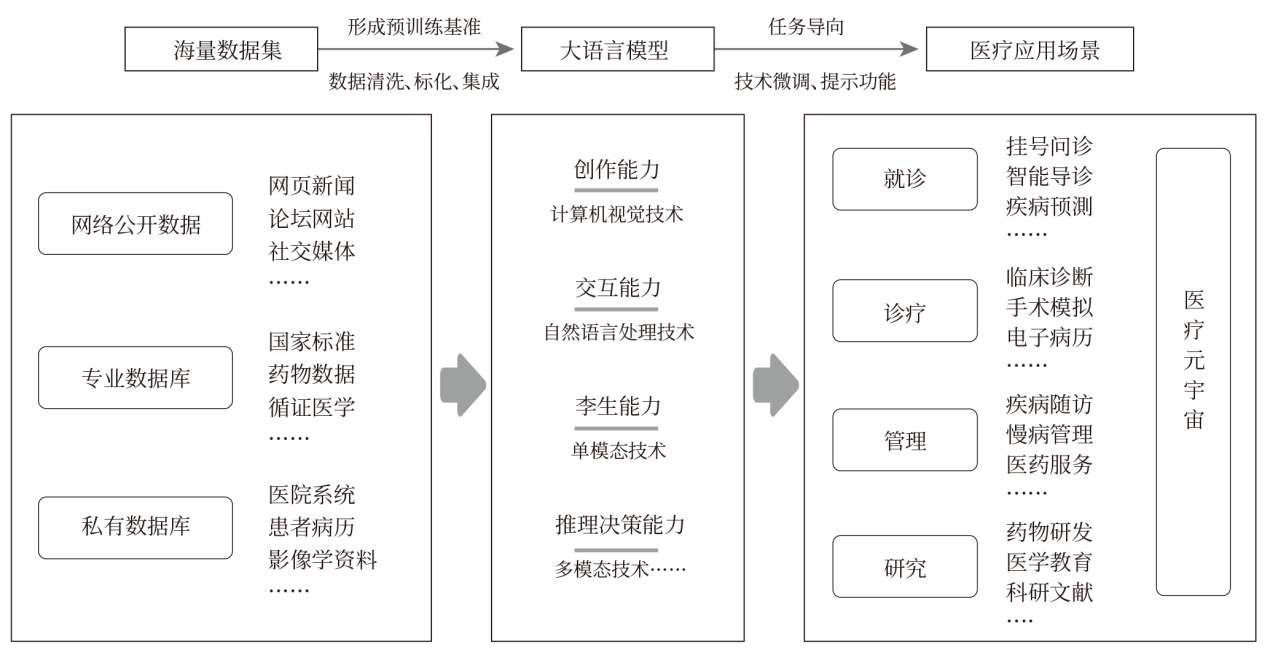
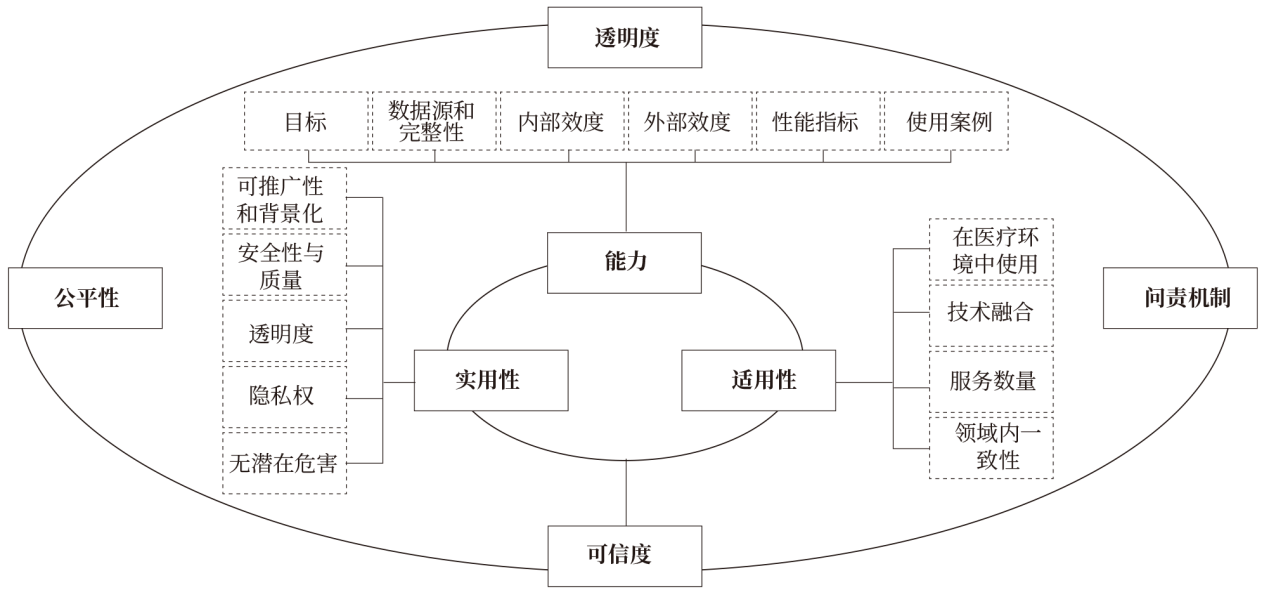
ISSN 2097-4205 CN 31-2200/R
| 评估工具 | 评估内容 | 分值范围 |
|---|---|---|
| Likert量表 | 评估响应准确性、信息量和可理解性 | 5种分类等级变量(强烈不同意、不同意、不置可否、同意、强烈同意 |
| Flesch阅读量表 | 评估模型输出文本的可读性,分值越高代表可读性越强 | 0~100分 |
| Flesch-Kincaid分级Coleman-Lia指数 | 理解文本需要的教育水平,或文本复杂性;分值高代表内容复杂 | / |
| DISCERN评分系统 | 评估响应质量、相关性、信息公平性;分值高代表信息质量高,内容表述充分 | 16~80分 |
 沪公网安备 31010402004887号
沪公网安备 31010402004887号